Kafka is a high-throughput, persistent, distributed messaging system that was originally developed at LinkedIn. It forms the backbone of uSwitch.com’s new data analytics pipeline and this post will cover a little about Kafka and how we’re using it.
Kafka is both performant and durable. To make it easier to achieve high throughput on a single node it also does away with lots of stuff message brokers ordinarily provide (making it a simpler distributed messaging system).
Messaging
Over the past 2 years we’ve migrated from a monolithic environment based around Microsoft .NET and SQL Server to a mix of databases, applications and services. These change over time: applications and servers will come and go.
This diversity is great for productivity but has made data analytics as a whole more difficult.
We use Kafka to make it easier for the assortment of micro-applications and services, that compose to form uSwitch.com, to exchange and publish data.
Messaging helps us decouple the parts of the infrastructure letting consumers and producers evolve and grow over time with less centralised coordination or control; I’ve referred to this as building a Data Ecosystem before.
Kafka lets us consume data in realtime (so we can build reactive tools and products) and provides a unified way of getting data into long-term storage (HDFS).
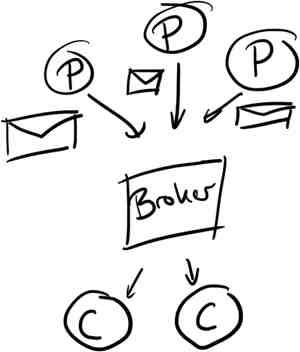
Kafka’s model is pretty general; messages are published onto topics by producers, stored on disk and made available to consumers. It’s important to note that messages are pulled by consumers to avoid needing any complex throttling in the event of slow consumption.
Kafka doesn’t dictate any serialisation it just expects a payload of byte[]. We’re using Protocol Buffers for most of our topics to make it easier to evolve schemas over time. Having a repository of definitions has also made it slightly easier for teams to see what events they can publish and what they can consume.
This is what it looks like in Clojure code using clj-kafka.
We use messages to record the products that are shown across our site, the searches that people perform, emails that are sent (and bounced), web requests and more. In total it’s probably a few million messages a day.
Metadata and State
Kafka uses Zookeeper for various bits of meta-information, including tracking which messages have already been retrieved by a consumer. To that end, it is the consumers responsibility to track consumption- not the broker. Kafka’s client library already contains a Zookeeper consumer that will track the message offsets that have been consumed.
As an side, the broker keeps no state about any of the consumers directly. This keeps it simple and means that there’s no need for complex structures kept in memory reducing the need for garbage collections.
When messages are received they are written to a log file (well, handed off to the OS to write) named after the topic; these are serial append files so individual writes don’t need to block or interfere with each other.
When reading messages consumers simply access the file and read data from it. It’s possible to perform parallel consumption through partitioned topics although this isn’t something we’ve needed yet.

Messages are tracked by their offset- letting consumers access from a given point into the topic. A consumer can connect and ask for all messages that Kafka has stored currently, or from a specified offset. This relatively long retention (compared to other messaging systems) makes Kafka extremely useful to support both real-time and batch reads. Further, because it takes advantage of disk throughput it makes it a cost-effective system too.
The broker can be configured to keep messages up to a specified quantity or for a set period of time. Our broker is configured to keep messages for up to 20 days, after that and you’ll need to go elsehwere (most topics are stored on HDFS afterwards). This characteristic that has made it so useful for us- it makes getting data out of applications and servers and into other systems much easier, and more reliable, than periodically aggregating log files.
Performance
Kafka’s performance (and the design that achieves it) is derived from the observation that disk throughput has outpaced latency; it writes and reads sequentially and uses the operating system’s file system caches rather than trying to maintain its own- minimising the JVM working set, and again, avoiding garbage collections.
The plot below shows results published within an ACM article; their experiment was to measure how quickly they could read 4-byte values sequentially and randomly from different storage.
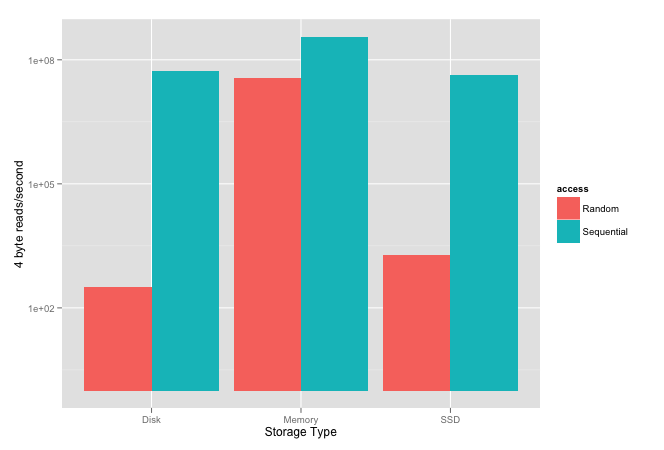
Please note the scale is logarithmic because the difference between random and sequential is so large for both SSD and spinning disks.
Interestingly, it shows that sequential disk access, spinning or SSD, is faster than random memory access. It also shows that, in their tests, sequential spinning disk performance was higher than SSD.
In short, using sequential reads lets Kafka get performance close to random memory access. And, by keeping very little in the way of metadata, the broker can be extremely lightweight.
If anyone is interested, the Kafka design document is very interesting and accessible.
Batch Load into HDFS
As I mentioned earlier, most topics are stored on HDFS so that we can maximise the amount of analysis we can perform over time.
We use a Hadoop job that is derived from the code included within the Kafka distribution.
The process looks a little like this:
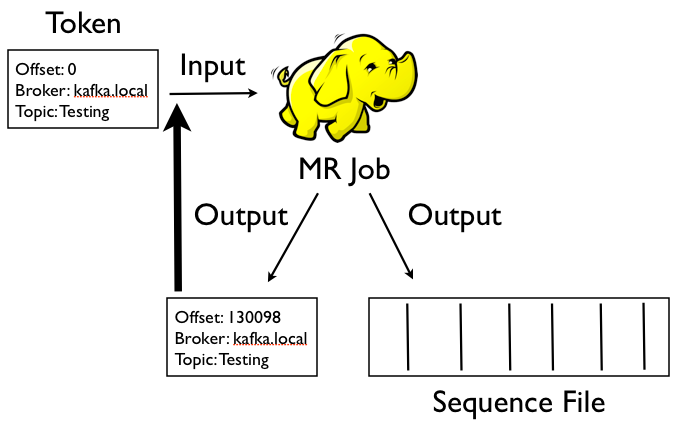
Each topic has a directory on HDFS that contains 2 further subtrees: these contain offset token files and data files. The input to the Hadoop job is an offset token file which contains the details of the broker to consume from, the message offset to read from, and the name of the topic. Although it’s a SequenceFile the value bytes contain a string that looks like this:
broker.host.com topic-name 102991
The job uses a RecordReader that connects to the Kafka broker and passes the message payload directly through to the mapper. Most of the time the mapper will just write the whole message bytes directly out which is then written using Hadoop’s SequenceFileOutputFormat (so we can compress and split the data for higher-volume topics) and Hadoop’s MultipleOutputs so we can write out 2 files- the data file and a newly updated offset token file.
For example, if we run the job and consume from offset 102991 to offset 918280, this will be written to the offset token file:
broker.host.com topic-name 918280
Note that the contents of the file is exactly the same as before just with the offset updated. All the state necessary to perform incremental loads is managed by the offset token files.
This ensures that the next time the job runs we can incrementally load only the new messages. If we introduce a bug into the Hadoop load job we can just delete one or more of the token files to cause the job to load from further back in time.
Again, Kafka’s inherent persistence makes dealing with these kinds of HDFS loads much easier than dealing with polling for logs. Previously we’d used other databases to store metadata about the daily rotated logs we’d pulled but there was lots of additional computation in splitting apart files that would span days- incremental loads with Kafka are infinitely cleaner and efficient.
Kafka has helped us both simplify our data collection infrastructure, letting us evolve and grow it more flexibly, and provided the basis for building real-time systems. It’s extremely simple and very easy to setup and configure, I’d highly recommend it for anyone playing in a similar space.
Related Stuff
As I publish this LinkedIn have just announced the release of Camus: their Kafka to HDFS pipeline. The pipeline I’ve described above was inspired by the early Hadoop support within Kafka but has since evolved into something specific for use at uSwitch.
Twitter also just published about their use of Kafka and Storm to provide real-time search.
I can also recommend reading “The Unified Logging Infrastructure for Data Analytics at Twitter” paper that was published late last year.
Finally, this post was based on a brief presentation I gave internally in May last year: Kafka a Little Introduction
.
]]>